
AEM Query Builder : Comprehensive Guide
AEM query builder is a tool/framework developed by adobe for writing simple and efficient queries in aem. In real world the performance of a website depends on its back end queries, which makes it really important to understand how query works in aem and how to write efficient queries.
After completing this tutorials, you will have clear understanding about:-
- What is Query Builder ?
- How to use Query Builder Debugger Tool in AEM.
- AEM Query Structure.
- AEM Query Standard Predicates.
- How to use Query Builder JAVA API.
- Troubleshooting AEM Query
What is Query Builder?
AEM Query Builder is a framework developed by adobe to build queries (JCR XPath underneath) for a query engine (OAK Query Engine) which are simple to compose. A query can be described as simple set of predicates in key value form.
How AEM query builder works internally:-
- AEM converts query builder queries into X-Path and sent it to Query Engine which again converts it to JCR SQL2 as X-Path and JCR SQL are deprecated from AEM 6.0(as jackrabbit upgraded to OAK).
- Executed by Oak query engine.
- Same query limits, traversal warnings apply as mentioned by OAK.
- Needs indexes for efficient queries (AEM 6.0 custom index needs to be created manually).
- AEM 6.3 onwards unindexed queries will give a warning/be denied.
It will be more clearer by below diagram.

Just a note AEM Query Builder is not:-
- A query engine itself (relies on JCR queries)
- does not have its own search index (relies on Oak indexes)
- or even cache (except a simple facet cache)
How to use Query Builder Debugger Tool in AEM:-
AEM comes with a Query Debugger tool using which you can execute search queries on the JCR (Java Content Repository) . Use this tool for dry run for your aem queries optimize them and then implement it in the code.
AEM Query Builder debugger URL:- http://localhost:4502/libs/cq/search/content/querydebug.html
Debugging AEM Query Logs:-
Debugging aem query is very critical when you are looking for its performance or any error in aem query. Follow below steps to enable AEM Query Debugger:-
- Navigate to http://localhost:4502/system/console/slinglog.
- Click on Add new logger (It might be useful to create a new log file for query, you can use any existing log file also.)
- Enter Log file Name(query.log).
- Set Log level to Debug or Trace.
- TRACE will also show filtering per node (useful when writing custom filtering)
- Avoid DEBUG or lower log level in production environment.
- Add below 3 class files for debugging.
com.day.cq.search
org.apache.jackrabbit.oak.plugins.index
org.apache.jackrabbit.oak.query

- Click on save.
- Go to Query builder console and run a simple query like:-
- type=dam:Asset

- Go to query.log file that we have created. [ http://localhost:4502/system/console/slinglog/tailer.txt?tail=1000&name=%2Flogs%2Fquery.log ]. You can see below logs specifying the query execution time, cost, index used and you can check how oak is converting xpath queries to SQL2 internally.

AEM Query Structure:-
Queries are always the backbone of any structure and from performance point of view. It becomes extremely important to write most optimized query. Lets decompose a query and see what all it consist of :-
- Predicates – If no parameter is provided, predicate type is mirrored in final query
- Parameter – Predicate Parameter
- Value – Value of predicate
Note:- Base on Predicate type, internally a predicate evaluator is resolved, which handles mapping of query to xpath, filtering of results, custom ordering if specified and facet extraction.

Handle Multiple Predicates of same Type:-
- Fixed numbering scheme
- Name = <number>_<type>
- Allows to define an order
type=cq:Page
1_property=jcr:content/cq:template
1_property.value=/apps/geometrixx/templates/homepage
2_property=jcr:content/jcr:title
2_property.value=English
List of AEM Standard Predicates:-
Here is the list of available standard predicates, that predicate evaluator uses to resolve at run time.
- path : This is used to search under a particular hierarchy. However we can create multiple path predicates to search under multiple paths (Resolves to PathPredicateEvaluator)
- path.self=true : If true searches the subtree including the main node given in path, if false searches the subtree only.
- path.exact=true : If true exact path is matched, if false all descendants are included.
- path.flat=true : If true searches only the direct children .
- type: It is used for searching particular nodetype only. ( For EX:- dam:Asset)(Resolves to TypePredicateEvaluator)
- property: This is used for search based on specific jcr property.(Resolves to JcrPropertyPredicateEvaluator)
- property.value : the property value to search . Mutilple values of a particular property could be given using N_property.value=xxx , where N is number from 1 to N and xxx is the value.
- property.depth : The number of additional levels to search under a node. eg. if property.depth=3 then the property is searched till 3 level from base node. It is mostly used for nested search.
- property.and : If multiple properties are present , by default an OR operator is applied. If you want an AND , you may use property.and=true
- property.operation : “equals” for exact match (default), “unequals” for unequality comparison, “like” for using the jcr:like xpath function , “not” for no match , (value param will be ignored) or “exists” for existence match .(value can be true – property must exist).
Example : To Check if both properties doesn’t Exist on metadata Node or 2 level down.path=/content/dam
nodename=metadata
1_property=tiff:ImageHeight
1_property.value=false
2_property=tiff:ImageWidth
2_property.value=false
1_property.operation=exists
2_property.operation=exists
property.and=true Respective XPath Query
/jcr:root/content/dam//*
[
fn:name() = 'metadata' and not(@tiff:ImageHeight)
and not(@tiff:ImageWidth)
]
- fulltext: It is used to search terms for fulltext search (This is case in sensitive search. fulltext predicate resolves to FulltextPredicateEvaluator)
- fulltext.relPath : can specify the relative path to search in (eg. property or subnode) eg. fulltext.relPath=jcr:content or fulltext.relPath=jcr:content/@cq:tags
- daterange : This predicate is used to search a date property range. (Resolves to DateRangePredicateEvaluator)
- daterange.property : Specify the date property which on which query needs to run.
- daterange.lowerBound : Fix a lower bound date range eg. 2010-07-25
- daterange.lowerOperation : “>” (default) or “>=”
- daterange.upperBound: Fix a upper bound date range eg. 2013-07-26
- daterange.upperOperation: “<” (default) or “<=”
- relativedaterange: It is an extension of daterange which uses relative offsets to server time. It also supports 1s 2m 3h 4d 5w 6M 7y. (Resolves to RelativeDateRangePredicateEvaluator)
- relativedaterange.lowerBound : Lower bound offset, default=0
- relativedaterange.upperBound : Upper bound Offset .
- nodename: This is used to search exact nodenames for the result set. It allows few wildcards like: nodename=text* will search for this and any character after it . nodename=text? will search for all records that starts with text but will not return result that contains only text. (Resolves to NodenamePredicateEvaluator).
Note:- During conversion to Xpath query * is converted to % and ? is converted to _ . For Example ‘metadata%’ (metadata node is considered, will return result for metadata,metadata1,metadata2 etc) but for ‘metadata_’ (metadata node is ignored, will only return result for metadata1, metadata2). Choose your wildcards very wisely. Hope it clears your doubt.
- tagid: This predicate is used to search for a particular tag on a page. You may specify the exact tagid of a tag in this predicate.(Note:- It searches for tags under /etc/tags also, so the service user that we are using for query must have access to this path also.)
- tagid.property: this may be used to specify the path of node where tags are stored.
- tagsearch : searches for matching tag first
- mainasset: mainasset=true means search only Dam Asset and not the subassets.
- group: This predicate is used to create logical conditions in your query (Resolves to PredicateGroupEvaluator). You can create complex conditions using OR & AND operators in different groups.
Note:- By default Two different predicates are separated by AND operator. Lets understand this scenario by a simple example.
Example 1 :-
fulltext=Management
group.p.or=true
group.1_path=/content/geometrixx/en
group.2_path=/content/dam/geometrixx
Final Xpath query will be created as (fulltext AND (path=… OR path=…))
Example 2 :-
fulltext=Management
group.p.or=true
group.1_group.path=/content/geometrixx/en
group.1_group.type=cq:Page
group.2_group.path=/content/dam/geometrixx
group.2_group.type=dam:Asset
Final Xpath query will be created as (fulltext AND ( (path= AND type=) OR (path= AND type=) ))
- orderBy: This predicate is used to sort the result sets obtained in the query. e.g. orderby=@jcr:score or orderby=@jcr:content/cq:lastModified
- orderby.sort: You may define the sorting way for the search results e.g. orderby.desc=true or orderby.sort = desc for descending and orderby.asc=true or orderby.sort=asc for ascending.
- orderby.case: support case insensitive orderby.case=ignore (since 6.2)
- orderby=mypredicate (eg: orderby=path) : this can also be used to sort by path.
Refining the Results: In order to refine the results there are some parameters which could be leveraged: - Multiple Ordering:- Multiple ordering can also be achieved using orderby predicate
1_orderby=@cq:tags&lt;br />2_orderby=@cq:lastModified&lt;br />3_orderby=nodename
- p.hits=full: Use this when you want to return all the properties in a node. Example
- p.hits=selective: Use this if you want to return selective properties in search result. Use this with p.properties=sling:resourceType jcr:primaryType Example :- p.properties = jcr:path
- p.nodedepth: Use this when you need properties of a node and its child nodes in the same search result. Use this with p.hits=full
- p.facets=true : This will be used to Search Facets based search for the assigned Query. If you want to calculate the count of tags which are present in your search result or you want to know how many templates for a particular page are there etc, you may go with Facets based search .
- p.guesstotal : The purpose of p.guessTotal parameter is to return the appropriate number of results that can be shown by combining the minimum viable p.offset and p.limit values. The advantage of using this parameter is improved performance with large result sets. This avoids calculating the full total (e.g calling result.getSize()) and reading the entire result set. For Example:-
path=/content
1_property=sling:resourceType
1_property.value=foundation/components/text
1_property.operation=like
p.guessTotal=true
orderby:path
The above query will return below response. You can see clearly that total number of records are 50 , but only 10 records are returned starting from offset 0.
success: true,
results: 10,
total: 50,
more: true,
offset: 0
Note:- Between two different Predicated AND operation is applied . Between two properties by default OR operation is applied.
Limiting AEM Query Results:-
- p.offset defines start of index means from which index you want to fetch records from query result.
- p.limit defines page size. In simple words how many records you want to fetch.
- Each query result will display results from p.offset to p.offset + p.limit
Note:- By default, the query builder json servlet displays a maximum of 10 hits. Adding p.limit=-1 parameter allows the servlet to display all query results.
For Example:- If p.offset=10 and p.limit=5 and total number of records returned are 100.

Debugging JSON servlet response:-
Note:- JSON servlet is a generic query endpoint and is prone to DoS attacks , you can either disable it or safe guard with query limits in Oak.
-Doak.queryLimitInMemory=500000<br>-Doak.queryLimitReads=100000
Query Builder JAVA API:-
There are three ways to use aem queries in java, personally i prefer using hash map as it is simple and easy to use. But it totally depends on your requirement which one to use when.
Write AEM Query in Java using HTTP request:-
Session session = request.getResourceResolver().adaptTo(Session.class);
PredicateGroup root = PredicateGroup.create(request.getParameterMap());
Query query = queryBuilder.createQuery(root, session)]
Write AEM Query in Java using Hash Map:-
Map predicateMap = new HashMap();
map.put("path", "/content");
map.put("type", "nt:file");
Query query = queryBuilder.createQuery(PredicateGroup.create(predicateMap), session);
//Get search results
SearchResult result = query.getResult();
List <Hit> list = result.getHits();
//Iterate query results
for (Hit hit : list) {
// Write your logic here
}
Write AEM Query in Java using Predicates:-
PredicateGroup group = new PredicateGroup();
group.add(new Predicate("path", "path").set("path", "/content"));
group.add(new Predicate("type", "type").set("type", "nt:file"));
Query query = queryBuilder.createQuery(group, session);
Troubleshooting AEM Query:-
- Query to check empty property value in jcr.
- Query builder does not provide any standard predicate through which we can check all nodes which has property abc values empty. But this use case can be achieved using Xpath queries.
- Go to Xpath query console. http://localhost:4502/crx/explorer/ui/search.jsp
- Select xpath and enter query in below format
/jcr:root/content/path/to/page/[@propertyName = '']
- For Example
/jcr:root/content/dam//*[@name= '']
where name is the property whose empty value i need to check. Just a note fn:name used in below screenshot is optional, i have used it to make my query more restrictive.

- Check your log file for “consider creating an index or changing the query”
- Root cause for above error is – queries that do not resolve to an index and traverse all JCR’s contents to collect results. This will cause slowness in system. Try creating index for your search properties.
- Large result set queries “*WARN* … java.lang.UnsupportedOperationException: The query read or traversed more than 100000 nodes. To avoid affecting other tasks, processing was stopped.”:-
- In AEM 6.3, by default, when a traversal of 100,000 is reached, the query fails and throws an exception. If your query requirement is to returning more than 1 lakh records then try increasing your query limit. Below are recommended values from adobe:-
-Doak.queryLimitInMemory=500000&lt;br />-Doak.queryLimitReads=100000
- You can add these parameters either in the AEM start script, or from JMX console. Go to JMX console–> QueryEngineSettings and change these limits.
- In AEM 6.3, by default, when a traversal of 100,000 is reached, the query fails and throws an exception. If your query requirement is to returning more than 1 lakh records then try increasing your query limit. Below are recommended values from adobe:-

- *WARN* org.apache.jackrabbit.oak.spi.query.Cursors$TraversingCursor Traversed ### nodes … consider creating an index or changing the query
- This error comes due to poorly restricted queries, try restricting your query by searching either on any unique property or more restrictive condition.
- How to get results in the query builder for a property whose value is not an empty string.
property.value=%_%
Hope i answered all your queries regarding aem query builder, if you still have any doubts feel free to drop a comment. In my follow up tutorial on query builder we will see about facets and aem custom predicate.
Understanding Query Execution Order and Performance in AEM QueryBuilder
One of the most misunderstood areas in AEM QueryBuilder optimization is the assumption that predicates execute in the same order they are written. In reality, QueryBuilder only acts as a translation layer. The actual execution strategy is decided later by the Oak Query Engine and the selected Lucene index.
Consider the following query:
type=dam:Asset
path=/content/dam/library
orderby=jcr:created
orderby.sort=desc
daterange.property=jcr:created
daterange.upperbound=2026-04-14
p.hits=selective
p.properties=jcr:path
p.limit=1000
p.guessTotal=1000
Let’s Assume:
- the query matches around 1 million DAM assets
- only the latest 1000 results are required
Oak performs below operation to fetch the results:-
- Query translation
- Index selection
- Cost calculation
- Lucene execution
- Result fetching
- Serialization optimizations
We have already details about these above, in this section i want to focus on orderby and sorting clause. Because this is the biggest performance bottleneck.
Always make sure that the property on which we are using orderby clause is made as ordered property in our lucene index by setting: ordered=true
By making it as ordered property in index:-
- read results directly in descending order
- stop after retrieving the first 1000 records
- avoid in-memory sorting completely
So our index will simply perform a Index lookup
→ sorted retrieval
→ early termination at 1000 rows
This is highly scalable and memory efficient.
Worst Case Scenario
If ordering support is missing. Oak will:
- retrieve all matching records
- materialize sort values
- sort results in JVM memory
- keep only the top 1000
LIMIT Processing:-
When using p.limit=1000, A common misconception is that LIMIT automatically restricts processing to 1000 rows.
That only happens when the index supports ordered retrieval. Otherwise, Oak may still process all 1 million matching records before applying the limit.
Total Count Optimization
When using p.guessTotal=1000 , This does not affect the main query execution. Instead, it optimizes total-hit calculation. Without guessTotal, Oak may compute the exact total match count, which can be expensive for very large result sets. Using guessTotal allows Oak to stop counting early and improves pagination performance.
Direct Count Configuration:-
While working with large queries, if your search result is not user permission dependent like fetch some content in dam and then pass it to third party or creating reports. Then i highly recommend leveraging Direct Count Configuration.
Examples
Get all Assets inside folder in AEM –
path=/content/dam/ <root-folder>
type=dam:Asset
p.limit=1
Check if folder contains any asset –
path=/content/dam/ <root-folder>
type=dam:Asset
p.limit=1
Use multiple values of same property in OR condition
type=dam:Asset
path=/content/dam
group.property=jcr:content/@dam:relativePath
group.property.1_value=we-retail/en/features/cart.png
group.property.2_value=we-retail/en/features/tracking.png
p.limit=-1
p.guessTotal=100
Use or condition with multiple node name and paths
type=dam:Asset
group.p.or=true
group.1_group.1_group.p.or=true
group.2_group.1_group.p.or=true
group.1_group.path=/content/dam/we-retail/en/features
group.1_group.1_group.1_nodename=cart.png
group.1_group.1_group.2_nodename=tracking.png
group.2_group.1_group.p.or=true
group.2_group.path=/content/dam/we-retail/en/features
group.2_group.1_group.1_nodename=cart.png
group.2_group.1_group.2_nodename=tracking.png
p.limit=-1
Use query with multiple paths
type=dam:Asset
group.p.or=true
group.1_path=/content/dam/we-retail/en/features
group.2_path=/content/dam/we-retail/en/features
p.limit=-1
Use Query on String Array Field in AEM
It was always a doubt for me, whether we can query on String array field in AEM. The answer is yes we can:-
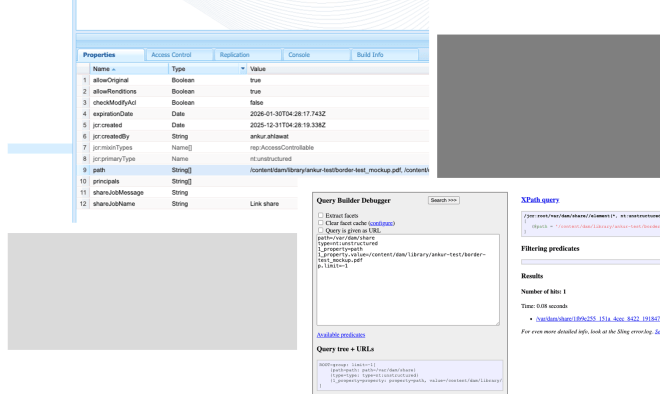
path=/var/dam/share
type=nt:unstructured
1_property=path
1_property.value=/content/dam/library/ankur-test/border-test_mockup.pdf
p.limit=-1
How to escape special characters in JCR SQL2 contains query:-
select * from [rep:User] AS a WHERE ISDESCENDANTNODE([/home/users]) AND CONTAINS(a.[profile/email],'aahlawa(@)gmail(.)co*')
//Note:- There are 2 ways to escape special characters using () or wrapping special characters in double quotes "".
How to put AND condition on single property in query builder:-
path= /content/dam
type=dam:Asset
1_property = assetType
1_property.1_value = jpeg
1_property.2_value = png
1_property.operation = unequals
1_property.and=true
Relative Date Range query Example :-
Below is the sample query. (To get all assets that are modified 5 days before)
path=/content/dam/library
type=dam:Asset
relativedaterange.property=jcr:content/jcr:lastModified
relativedaterange.lowerBound=-5d (If no upperBound is specified, it is treated as 0, indicating current time)
p.limit=-1
Query with multiple paths and only direct decedents Example:-
Below is the sample query. (To get all direct folders from multiple paths)
type=nt:base
property=jcr:primaryType
group.1_path=/content/dam/library
group.1_path.flat=true
property.1_value=sling:OrderedFolder
group.2_path=/content/dam/library/workfront/creative
group.2_path.flat=true
property.3_value=nt:folder
property.2_value=sling:Folder
group.p.or=true
p.limit=-1
Why IS NULL in JCR-SQL2 May Cause Traversal While Query Builder operation=not Can Use Oak Indexes in Adobe Experience Manager
When working with queries in Apache Jackrabbit Oak within Adobe Experience Manager, it is important to understand how different query syntaxes interact with Oak indexes.
In JCR-SQL2, conditions such as IS NULL are generally not efficiently supported by property indexes because Oak indexes only store entries for properties that actually exist on nodes. As a result, when a query checks for property IS NULL, the query engine often cannot rely on the index and may fall back to repository traversal, which can significantly degrade performance in large repositories.
However, when using Query Builder, the predicate property.operation=not (e.g., group.1_property.operation=not) is internally translated by AEM’s query engine into a constraint that can sometimes leverage existing indexes during execution planning.
In practice, this means that while a JCR-SQL2 query checking IS NULL may result in traversal, an equivalent Query Builder query using operation=not may still pick up an index depending on the index configuration and query plan. Therefore, as a developer we should always verify query execution using tools like the Explain Query or Query Performance Tool in AEM to ensure that the query is using the intended index and not degrading into traversal.
Leave a Reply