
AEM OAK Indexing : Comprehensive Guide
AEM oak indexing is a very crucial and important concept as performance of all queries depends upon how oak has indexed the properties in back-end. I have received multiple request to write on indexing in aem as this is a very vast concept and very limited knowledge and documentation is available on internet. Because if no index is found for a specific query, then whole repository will be traversed, which is a very costly operation and might result in temporary freeze/hang of system/instance if multiple full path traversal queries are fired.
In this tutorial i will try my best to describe what are the type of index available in oak and which one should be used when in aem. As oak does not index as much content by default as Jackrabbit 2 does earlier and we have to create custom index to improve performance of query. So I will also cover how to create custom lucene and property index as part of this tutorial.
After completing this tutorial you will have clear understanding about:-
- Overview of OAK indexes.
- Analyze queries in aem
- Create custom property index in aem.
- Create custom lucene index in aem
- Troubleshooting aem queries.
Overview of OAK indexes:-
In order to perform queries well, oak supports indexing of content that is stored in the repository. There are three types of indexing mode available that defines defines how comparing is performed, and when the index content gets updated:-
- Synchronous Indexing – (Generally used with Property Based index)
- Asynchronous Indexing – (Generally used with Lucene based Index )
- Near Real Time (NRT) Indexing
Note:- Out of these AEM uses only two modes synchronous Indexing and asynchronous Indexing.
For updating indexes oak uses commit editors, which are responsible for updating index content based on changes in main content. Currently there are four built in editors available in oak:-
- PropertyIndexEditor
- LuceneIndexEditor
- SolrIndexEditor
- ReferenceEditor
There are 3 main types of indexes available in AEM :-
- Lucene – asynchronous (full text and property)[Highly preferred only drawback is it is asynchronous ]
- Property – synchronous [ Prefer only when you need synchronous results ]
- Solr – asynchronous (Least preffred)
- Ordered (Deprecated) – As ordered indexes are deprecated, so we are not going to discuss about them in this tutorial.
Lets see in detail about different type of aem index provided by oak.
Analyze queries in aem:-
Go to Query performance tool Tools -> Operations -> Dashboard -> Diagnosis -> Query Performance.
Direct url AEM 6.2:- http://localhost:4502/libs/granite/operations/content/diagnosis/tool.html/granite:queryperformance
Direct url AEM 6.3:- http://localhost:4502/libs/granite/operations/content/diagnosis/tool.html/granite_queryperformance
AEM 6.1 on wards Explain query tool was made a part of product itself. For detailed level of debugging you can also install acs common explain tools https://adobe-consulting-services.github.io/acs-aem-tools/features/explain-query/index.html . But in this tutorial we are going to use only those features that comes out of the box with product.
Once oak transformed the given query into SQL-2, each index is consulted to estimate the cost for the query. Once that is completed, the results from the cheapest index are retrieved. If you have both property and lucene index available for your property then cost is calculated against both type of indexes and respective index will be picked. For example
When you open query performance tool. First tab will show you the list of slow performing queries, second tab shows list of popular queries. These tabs helps in identifying our slow and most popular queries, so that we can further optimize them if required. Third tab is Explain query Tab, this is the tab in which we are interested.
- The language drop-down provides support for running queries in 3 different languages JCR-SQL2, SQL and XPath, Personally i prefer running queries in form of xpath as i get xpath query syntax easily from querybuilder tool.
- In query tab, enter you query that you want to analyze.
- Click on Explain button to analyze the query.

Lets understand this scenario with a use case. I want to get all nodes under /content/dam which is having property code=11 and primaryType is nt:unstructured.
First Scenario:- I have created only lucene index for property code.

Go to explain tool and run below query
/jcr:root/content/dam//element(*, nt:unstructured) [ @code = '11' ]

Note:- If cost is infinity , it means that the given index is never used.
Second Scenario:- I have both property and lucene index for property code. and run same query again

In this case property index will be picked as we know the property constraint and its value.

Conclusion:-
If we know exact property on which constraint has to be applied and its value ad it is not bounded by node type then its better to create a property index as it will take priority:-
/jcr:root/content/dam//element(*, dam:Asset) [ @code = '21' ]
If we don’t know exact property on which constraint has to be applied and have to go for fulltext search (jcr:contains) then its better to create a lucene index as it will take priority (If nodetype constraint is available in query like (nt:unstructured in this example) which we know mostly):-
/jcr:root/content/dam//element(*, dam:Asset) [ jcr:contains(., '21') ]
Note:– Lucene index works on node type, if no property index is available and nodetype matches then it will use lucene index. As it will return lower cost instead of full repository traversal. You can use aggregation if you want to search on nested nodes.
Create custom property index in aem:-
Creating custom property index is very simple and it is mostly useful when we want synchronization (means getting query result as soon as node property is updated without any delay) , and can evaluate equality and not null conditions of a query or we have queries that have property constraints but are not full-text. Follow below steps to create a custom property index in aem:-
- Open CRXDE and navigate to http://localhost:4502/crx/de/index.jsp
- Create a new node under oak:index. (Custom index can be created under /oak:index only)
- Enter name of PropertyIndex node( you can give any name but its good to keep it meaningful means it should tell the purpose of this node ), and enter node type to oak:QueryIndexDefinition.
- Below two are the only mandatory property for create a custom property index::-
- type: property (of type String) [Type of index as we want to create property index that’s why its value is property]
- propertyNames: code (of type Name[]) [Enter name of property for which you want to create index]
- Click save all and save your changes.
That’s it you have successfully created a custom property index. As i said It’s very simple isn’t it. One thing required is the knowledge when and where which type of index is required for optimizing aem queries.
Note:- It is recommended to index one property per index although propertyNames is an array. Because if multiple properties are indexed within one index, then the index contains all nodes that has either one of the properties, which can make the query less efficient.
There are few more optional property that you can set at your propertyIndex node,as per your requirement:-
- declaringNodeTypes (Name, multi-valued): the index only applies to a certain node type.
- unique (Boolean): if set to true, a uniqueness constraint on this property is added. Ensure you set declaringNodeTypes, otherwise all nodes of the repository are affected (which is most likely not what you want), and you are not able to version the node.
- includedPaths (String, multi-valued): the paths that are included (‘/’ if not set). Since Oak version 1.4 (OAK-3263). The index is only used if the query has a path restriction that is not excluded, and part of the included paths.
- excludedPaths (String, multi-valued): the paths where this index is excluded (none if not set). Since Oak version 1.4 (OAK-3263). The index is only used if the query has a path restriction that is not excluded, and part of the included paths.
- valuePattern (String) : A regular expression of all indexed values. The index is used for equality conditions where the value matches the pattern, and for “in(…)” queries where all values match the pattern. The index is not used for “like” conditions. Since Oak version 1.7.2 (OAK-4637).
- valueExcludedPrefixes: The index is used for equality conditions where the value does not start with the given prefix, and the prefix does not start with the value, similarly for “in(…)” conditions, and similarly for “like” conditions. and for “in(…)” queries where all values match the pattern. Since Oak version 1.7.2 (OAK-4637).
- valueIncludedPrefixes : The index is used for equality conditions where the value starts with the given prefix, similarly for “in(…)” conditions, and similarly for “like” conditions. Since Oak version 1.7.2 (OAK-4637).
- entryCount (Long): the estimated number of path entries in the index, to override the cost estimation (a high entry count means a high cost).
- keyCount (Long): the estimated number of keys in the index, to override the cost estimation (a high key count means a lower cost and a low key count means a high cost when searching for specific keys; has no effect when searching for “is not null”).
- reindex (Boolean): if set to true, the full content is re-indexed. This can take a long time, and is run synchronously with storing the index (except with an async index). See “Reindexing” below for details.
For mode details visit https://jackrabbit.apache.org/oak/docs/query/property-index.html
Create custom lucene index in aem:-
Lucene index are the most widely used custom indexes in aem as they are async and provide many capabilities as compared to property index like evaluating equality, not null, sorting, full-text, and range queries. Lucene index are the first choice if you want search based on node types, use aggregation or want to use synonyms or steaming in search. Lets see how to create custom lucene index and leverage these features:-
- Open CRXDE and navigate to http://localhost:4502/crx/de/index.jsp
- Create a new node under oak:index. (Custom index can be created under /oak:index only)
- Enter name of LuceneIndex node( you can give any name but its good to keep it meaningful means it should tell the purpose of this node ), and enter node type to oak:QueryIndexDefinition.
- Enter below Mandatory property for create a custom property index::-
- type: lucene(of type String) [Type of index as we want to create property index that’s why its value is property]
- asysc : async
- compatVersion: 2 (It is important to provide compact version as it tells oak which version specification to pick, from AEM 6 version 2 is recommended)
- Click save all and save your changes.
/oak:index/code - jcr:primaryType = "oak:QueryIndexDefinition" - compatVersion = 2 - Mandatory property - type = "lucene" - Mandatory property - async = "async" - Mandatory property + indexRules - jcr:primaryType = "nt:unstructured" + nt:unstructured --- NodeType on which we want to run query(Means only those records will be indexed that contains nodetype nt:unstructured, It can be any node type dam:Asset, nt:base.) + properties -- Define all your properties under this node - jcr:primaryType = "nt:unstructured" + code -- First Property - propertyIndex = true - name = "code"
Note:- Its is recommended to create one index definition, each index definition has one index rules and under one index rules we can have multiple nodetype and properties associated with each node type on which we want to create index.
Few more optional properties are available at index definition level. Refer OAK Documentation for more info.
Implement Aggregation on custom lucene index in aem:-
Sometimes it is useful to include the contents of descendant nodes into a single node to easier search on content that is scattered across multiple nodes. In simple words, generally lucene index only one node type, but if we want to inherit properties from its decendent nodes also on parent node we ca use aggregation.
Lets understand it with a use case, consider you have created a lucene index on nodetype dam:Asset, but some of your properties resides on dam:Asset/jcr:content or dam:Asset/jcr:content/metadata/ or dam:Asset/jcr:content/metadata/* and you want them to index also in this custom lucene index only. You can achieve this by using aggregation.
Implementing Aggregation is very simple. Follow below steps to implement aggregation:-
- Go to your custom lucene index node under /oak:Index
- Right click and create a node of type nt:unstructured and name as aggregates.
- Under aggregates node create another nt:unstructured node and enter name of parent node on which you want aggregation(For Example in our case dam:Asset)
- Create another nt:unstructured node under dam:Asset and name it as include0. Enter below properties on this node.
- path (String) — jcr:content (child node name)
Note:- You can have multiple node type under aggregation and each nodeType will have multiple includes based on the requirement, with incremented version include <number>.
- Repeat the above steps for all child nodes that you want to make part of aggregation. Like create two mode nodes with name include1 and include2 with path value as jcr:content/metadata and jcr:content/metadata/*.
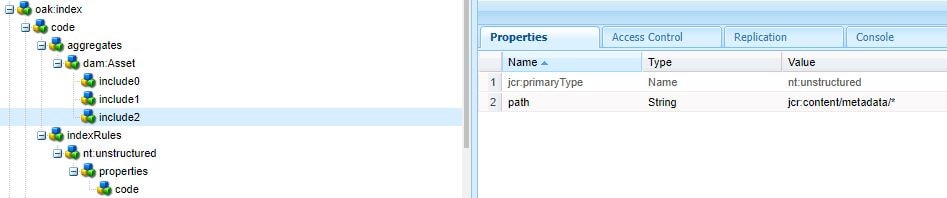
That’s it you have implemented aggregation on custom lucene index now properties from dam:Asset/jcr:content or dam:Asset/jcr:content/metadata/ or dam:Asset/jcr:content/metadata/* will be index on dam:Asset node.
As i have said earlier aem oak indexing is a very vast topic and is very difficult to cover in a single post. That’s why i am ending this post here and will see stemming synonyms , stop words and more in follow up posts.
Troubleshooting aem queries:-
Few more important points that a developer should always keep in mind while working with aem oak indexing are mentioned below:-
- Deciding when a custom index is required-
Nearly all application queries using custom properties which might need a custom index created for faster processing. Now the million dollar question is, how we will identify that when we need a custom index in aem. If you see log message like below this indicates that a new index is needed:
23.09.2017 14:33:59.466 *WARN* [qtp1832135175-163] org.apache.jackrabbit.oak.spi.query.Cursors$TraversingCursor Traversed 1000 nodes with filter Filter(query=select * from [nt:base] where foo = 'bar', path=*, property=[foo=[bar]]); consider creating an index or changing the query
Note:- The important part is TraversingCursor, it’s hinting that the highlighted query was not served by an index. In this example, to solve the problem we would need to create an index on the property foo.
Another case is, it might happen that the TraversingCursor still serve the query if an existing index cost is higher than traversing a particular sub-tree.
Analyze your query log file and check for below log statement:
23.09.2017 15:01:08.633 *WARN* [qtp1054115870-158] org.apache.jackrabbit.oak.plugins.index.property.strategy.ContentMirrorStoreStrategy Traversed 10000 nodes (30000 index entries) using index foo with filter Filter(query=select * from [nt:base] where [foo] is not null, path=*, property=[foo=[is not null]])
Note:- This is highlighting that the query is being handled by an index. ContentMirrorStoreStrategy is used only the property index. Nevertheless, the index is becoming big. more than 10000 nodes by default. The actions from here to be taken are if there’s any way to optimize the query itself or increase the threshold. In our specific example the query can be optimised by providing a specific node type and/or a path restriction. Otherwise the threshold can be configured by the system property oak.traversing.warn. See OAK-2720 for more details.
- Checking when async indexing is started and completed
Go to query logs and check for below snippet. It is available only at INFO level:-
22.09.2017 14:26:23.517 *INFO* [FelixStartLevel] org.apache.jackrabbit.oak.plugins.index.IndexUpdate Reindexing Traversed #10000 /jcr:system/jcr:versionStorage/c8/5f ... 22.09.2017 14:28:51.999 *INFO* [pool-8-thread-1] org.apache.jackrabbit.oak.plugins.index.IndexUpdate Indexing report - /oak:index/counter*(708) - /oak:index/authorizables*(159) - /oak:index/cqPageLucene*(1913) - /oak:index/ntBaseLucene*(444) - /oak:index/cqTagLucene*(512) - /oak:index/workflowDataLucene*(116) ... 22.09.2017 14:28:52.009 *INFO* [pool-8-thread-1] org.apache.jackrabbit.oak.plugins.index.AsyncIndexUpdate Reindexing (async) completed for indexes: [/oak:index/counter*(708), /oak:index/authorizables*(159), /oak:index/cqPageLucene*(1913), /oak:index/ntBaseLucene*(444), /oak:index/cqTagLucene*(512), /oak:index/workflowDataLucene*(116)] in 30.36 s
- When you should use Solr:-
You should never use Solr as the first option always try to achieve your use case using Lucene instead. By being at remote it can be affected by network latency. It’s good to use in case of :-
- Geo location
- Full text search
- Search term suggestions
- What to do if i have two queries full text and property constraint on same property:-
In this case you should create two index one property index and one lucene index. I tried to run this use case and when you search based on property constraint property index is picked and when you want same property in full text query lucene index is picked.
Leave a Reply